A Step-by-Step Guide to Synthesizing Adversarial Examples
Synthesizing adversarial examples for neural networks is surprisingly easy: small, carefully-crafted perturbations to inputs can cause neural networks to misclassify inputs in arbitrarily chosen ways. Given that adversarial examples transfer to the physical world and can be made extremely robust, this is a real security concern.
In this post, we give a brief introduction to algorithms for synthesizing adversarial examples, and we walk through the process of implementing attacks in TensorFlow, building up to synthesizing a robust adversarial example following this technique.
This post is an executable Jupyter notebook: you’re encouraged to download it and experiment with the examples yourself!
Setup
We choose to attack an Inception v3 network trained on ImageNet. In this section, we load a pre-trained network from the TF-slim image classification library. This part isn’t particularly interesting, so feel free to skip this section.
import tensorflow as tf
import tensorflow.contrib.slim as slim
import tensorflow.contrib.slim.nets as nets
tf.logging.set_verbosity(tf.logging.ERROR)
sess = tf.InteractiveSession()
First, we set up the input image. We use a tf.Variable instead of a tf.placeholder because we will need it to be trainable. We can still feed it when we want to.
image = tf.Variable(tf.zeros((299, 299, 3)))
Next, we load the Inception v3 model.
def inception(image, reuse):
preprocessed = tf.multiply(tf.subtract(tf.expand_dims(image, 0), 0.5), 2.0)
arg_scope = nets.inception.inception_v3_arg_scope(weight_decay=0.0)
with slim.arg_scope(arg_scope):
logits, _ = nets.inception.inception_v3(
preprocessed, 1001, is_training=False, reuse=reuse)
logits = logits[:,1:] # ignore background class
probs = tf.nn.softmax(logits) # probabilities
return logits, probs
logits, probs = inception(image, reuse=False)
Next, we load pre-trained weights. This Inception v3 has a top-5 accuracy of 93.9%.
import tempfile
from urllib.request import urlretrieve
import tarfile
import os
data_dir = tempfile.mkdtemp()
inception_tarball, _ = urlretrieve(
'https://download.tensorflow.org/models/inception_v3_2016_08_28.tar.gz')
tarfile.open(inception_tarball, 'r:gz').extractall(data_dir)
restore_vars = [
var for var in tf.global_variables()
if var.name.startswith('InceptionV3/')
]
saver = tf.train.Saver(restore_vars)
saver.restore(sess, os.path.join(data_dir, 'inception_v3.ckpt'))
Next, we write some code to show an image, classify it, and show the classification result.
import json
import matplotlib.pyplot as plt
imagenet_json, _ = urlretrieve(
'https://anishathalye.com/media/2017/07/25/imagenet.json')
with open(imagenet_json) as f:
imagenet_labels = json.load(f)
def classify(img, correct_class=None, target_class=None):
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 8))
fig.sca(ax1)
p = sess.run(probs, feed_dict={image: img})[0]
ax1.imshow(img)
fig.sca(ax1)
topk = list(p.argsort()[-10:][::-1])
topprobs = p[topk]
barlist = ax2.bar(range(10), topprobs)
if target_class in topk:
barlist[topk.index(target_class)].set_color('r')
if correct_class in topk:
barlist[topk.index(correct_class)].set_color('g')
plt.sca(ax2)
plt.ylim([0, 1.1])
plt.xticks(range(10),
[imagenet_labels[i][:15] for i in topk],
rotation='vertical')
fig.subplots_adjust(bottom=0.2)
plt.show()
Example image
We load our example image and make sure it’s classified correctly.
import PIL
import numpy as np
img_path, _ = urlretrieve('https://anishathalye.com/media/2017/07/25/cat.jpg')
img_class = 281
img = PIL.Image.open(img_path)
big_dim = max(img.width, img.height)
wide = img.width > img.height
new_w = 299 if not wide else int(img.width * 299 / img.height)
new_h = 299 if wide else int(img.height * 299 / img.width)
img = img.resize((new_w, new_h)).crop((0, 0, 299, 299))
img = (np.asarray(img) / 255.0).astype(np.float32)
classify(img, correct_class=img_class)

Adversarial examples
Given an image , our neural network outputs a probability distribution over labels, . When we craft an adversarial input, we want to find an where is maximized for a target label : that way, our input will be misclassified as the target class. We can ensure that doesn’t look too different from the original by constraining ourselves to some box with radius , requiring that .
In this framework, an adversarial example is the solution to a constrained optimization problem that we can solve using backpropagation and projected gradient descent, basically the same techniques that are used to train networks themselves. The algorithm is simple:
We begin by initializing our adversarial example as . Then, we repeat the following until convergence:
Initialization
We start with the easiest part: writing a TensorFlow op for initialization.
x = tf.placeholder(tf.float32, (299, 299, 3))
x_hat = image # our trainable adversarial input
assign_op = tf.assign(x_hat, x)
Gradient descent step
Next, we write the gradient descent step to maximize the log probability of the target class (or equivalently, minimize the cross entropy).
learning_rate = tf.placeholder(tf.float32, ())
y_hat = tf.placeholder(tf.int32, ())
labels = tf.one_hot(y_hat, 1000)
loss = tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=[labels])
optim_step = tf.train.GradientDescentOptimizer(
learning_rate).minimize(loss, var_list=[x_hat])
Projection step
Finally, we write the projection step to keep our adversarial example visually close to the original image. Additionally, we clip to to keep it a valid image.
epsilon = tf.placeholder(tf.float32, ())
below = x - epsilon
above = x + epsilon
projected = tf.clip_by_value(tf.clip_by_value(x_hat, below, above), 0, 1)
with tf.control_dependencies([projected]):
project_step = tf.assign(x_hat, projected)
Execution
Finally, we’re ready to synthesize an adversarial example. We arbitrarily choose “guacamole” (imagenet class 924) as our target class.
demo_epsilon = 2.0/255.0 # a really small perturbation
demo_lr = 1e-1
demo_steps = 100
demo_target = 924 # "guacamole"
# initialization step
sess.run(assign_op, feed_dict={x: img})
# projected gradient descent
for i in range(demo_steps):
# gradient descent step
_, loss_value = sess.run(
[optim_step, loss],
feed_dict={learning_rate: demo_lr, y_hat: demo_target})
# project step
sess.run(project_step, feed_dict={x: img, epsilon: demo_epsilon})
if (i+1) % 10 == 0:
print('step %d, loss=%g' % (i+1, loss_value))
adv = x_hat.eval() # retrieve the adversarial example
step 10, loss=4.18923
step 20, loss=0.580237
step 30, loss=0.0322334
step 40, loss=0.0209522
step 50, loss=0.0159688
step 60, loss=0.0134457
step 70, loss=0.0117799
step 80, loss=0.0105757
step 90, loss=0.00962179
step 100, loss=0.00886694
This adversarial image is visually indistinguishable from the original, with no visual artifacts. However, it’s classified as “guacamole” with high probability!
classify(adv, correct_class=img_class, target_class=demo_target)

Robust adversarial examples
Now, we go through a more advanced example. We follow our approach for synthesizing robust adversarial examples to find a single perturbation of our cat image that’s simultaneously adversarial under some chosen distribution of transformations. We could choose any distribution of differentiable transformations; in this post, we’ll synthesize a single adversarial input that’s robust to rotation by .
Before we proceed, let’s check if our previous example is still adversarial if we rotate it, say by an angle of .
ex_angle = np.pi/8
angle = tf.placeholder(tf.float32, ())
rotated_image = tf.contrib.image.rotate(image, angle)
rotated_example = rotated_image.eval(feed_dict={image: adv, angle: ex_angle})
classify(rotated_example, correct_class=img_class, target_class=demo_target)

Looks like our original adversarial example is not rotation-invariant!
So, how do we make an adversarial example robust to a distribution of transformations? Given some distribution of transformations , we can maximize , subject to . We can solve this optimization problem via projected gradient descent, noting that is and approximating with samples at each gradient descent step.
Rather than manually implementing the gradient sampling, we can use a trick to get TensorFlow to do it for us: we can model our sampling-based gradient descent as doing gradient descent over an ensemble of stochastic classifiers that randomly sample from the distribution and transform their input before classifying it.
num_samples = 10
average_loss = 0
for i in range(num_samples):
rotated = tf.contrib.image.rotate(
image, tf.random_uniform((), minval=-np.pi/4, maxval=np.pi/4))
rotated_logits, _ = inception(rotated, reuse=True)
average_loss += tf.nn.softmax_cross_entropy_with_logits(
logits=rotated_logits, labels=labels) / num_samples
We can reuse our assign_op and project_step, though we’ll have to write a new optim_step for this new objective.
optim_step = tf.train.GradientDescentOptimizer(
learning_rate).minimize(average_loss, var_list=[x_hat])
Finally, we’re ready to run PGD to generate our adversarial input. As in the previous example, we’ll choose “guacamole” as our target class.
demo_epsilon = 8.0/255.0 # still a pretty small perturbation
demo_lr = 2e-1
demo_steps = 300
demo_target = 924 # "guacamole"
# initialization step
sess.run(assign_op, feed_dict={x: img})
# projected gradient descent
for i in range(demo_steps):
# gradient descent step
_, loss_value = sess.run(
[optim_step, average_loss],
feed_dict={learning_rate: demo_lr, y_hat: demo_target})
# project step
sess.run(project_step, feed_dict={x: img, epsilon: demo_epsilon})
if (i+1) % 50 == 0:
print('step %d, loss=%g' % (i+1, loss_value))
adv_robust = x_hat.eval() # retrieve the adversarial example
step 50, loss=0.0804289
step 100, loss=0.0270499
step 150, loss=0.00771527
step 200, loss=0.00350717
step 250, loss=0.00656128
step 300, loss=0.00226182
This adversarial image is classified as “guacamole” with high confidence, even when it’s rotated!
rotated_example = rotated_image.eval(feed_dict={image: adv_robust, angle: ex_angle})
classify(rotated_example, correct_class=img_class, target_class=demo_target)

Evaluation
Let’s examine the rotation-invariance of the robust adversarial example we produced over the entire range of angles, looking at over .
thetas = np.linspace(-np.pi/4, np.pi/4, 301)
p_naive = []
p_robust = []
for theta in thetas:
rotated = rotated_image.eval(feed_dict={image: adv_robust, angle: theta})
p_robust.append(probs.eval(feed_dict={image: rotated})[0][demo_target])
rotated = rotated_image.eval(feed_dict={image: adv, angle: theta})
p_naive.append(probs.eval(feed_dict={image: rotated})[0][demo_target])
robust_line, = plt.plot(thetas, p_robust, color='b', linewidth=2, label='robust')
naive_line, = plt.plot(thetas, p_naive, color='r', linewidth=2, label='naive')
plt.ylim([0, 1.05])
plt.xlabel('rotation angle')
plt.ylabel('target class probability')
plt.legend(handles=[robust_line, naive_line], loc='lower right')
plt.show()
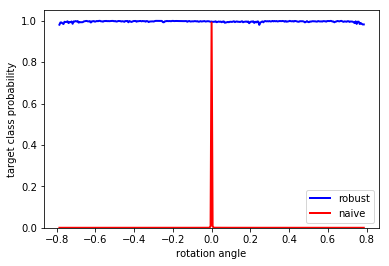
It’s super effective!